Facebook blames Monday's outage on "an error of our own making"
Yesterday's six-hour outage affecting Facebook, Facebook Messenger, Instagram, and Whats App had a severe impact on more than just users of those apps. The outage might have cost Facebook over $100 million in lost advertising revenue as the company happens to own all of the aforementioned apps.
The company points the finger of blame at itself and says that the outage started when Facebook engineers were working on "routine maintenance." In a blog post written by the firm's VP of infrastructure, Santosh Janardhan, the executive says that the company is trying to learn from the outage so that it doesn't get repeated.
Facebook's outage cost Mark Zuckerberg billions of dollars
Janardham adds, "This outage was triggered by the system that manages our global backbone network capacity. The backbone is the network Facebook has built to connect all our computing facilities together, which consists of tens of thousands of miles of fiber-optic cables crossing the globe and linking all our data centers." Data centers, like Facebook users, come in different sizes and shapes.
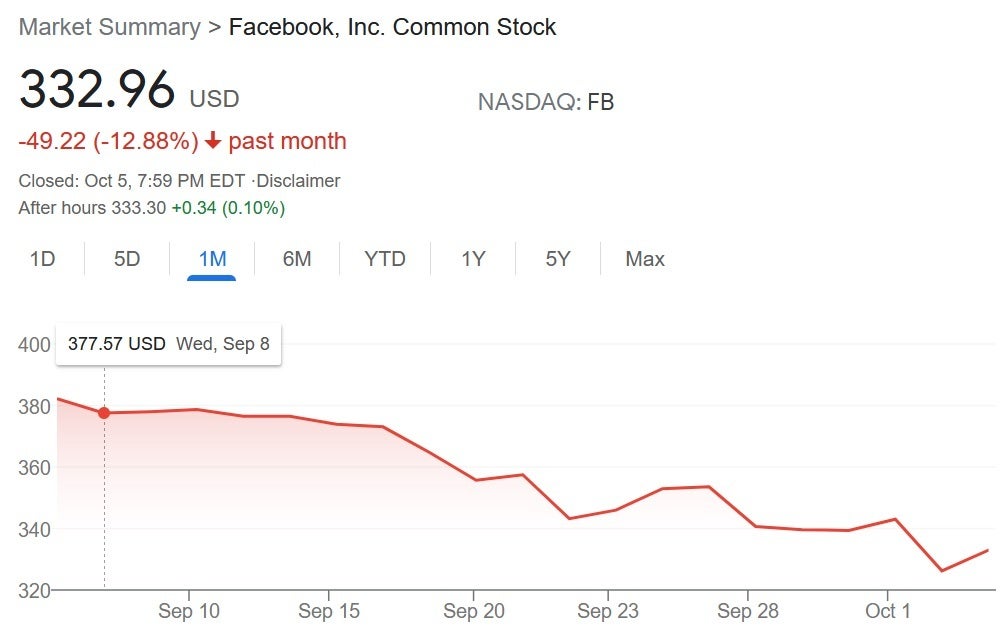
Facebook's shares have had a really rough month hitting Mark Zuckerberg squarely in his wallet
Some data centers are big buildings that house huge numbers of computers that store data and do the heavy lifting to keep the network running. Others are smaller facilities where device owners' requests for data are sent and then moved using Facebook's backbone network to larger data centers. That is where the data that your app needs is discovered and sent to your phone.
Hours after the outage started, Facebook's shares declined to reduce the worth of co-founder and CEO Mark Zuckerberg by $6 billion. Over the last month, Facebook shares declined by 12.88% dropping Zuckerberg's personal worth down from nearly $140 billion to $120.9 billion. However, we don't expect to see Facebook run a bake sale for its beleaguered chief executive.
Routers are used to determine where all of the incoming and outgoing data should be sent. And occasionally Facebook engineers need to take the backbone offline for maintenance. And yesterday, a command was issued that was supposed to check the available capacity of Facebook's backbone. Instead, it accidentally took down all of the connections in the backbone network which disconnected Facebook's data centers around the world.
Facebook has a system in place that is designed to audit commands to make sure that an accidental outage like the one that went down yesterday doesn't take place. But the audit tool had its own bug that prevented it from stopping the command from shutting down the system.
Facebook says that it will learn from the outage so that it never happens again
A second problem affected Facebook's DNS servers. As stated in today's blog post, "The end result was that our DNS servers became unreachable even though they were still operational. This made it impossible for the rest of the internet to find our servers." Facebook notes that everything happened so fast that its engineers had two big problems: because its networks were down, the data centers could not be accessed by normal means and the loss of DNS broke the tools that Facebook would normally use to investigate and fix outages.
Once Facebook was able to restore its backbone network connectivity, everything came back up. But Facebook had another problem to consider. If it turned all of its services back on at once, the amount of traffic running through the system could cause the system to crash again. But thanks to the "storm drills" that Facebook has been practicing, it was well prepared to handle the incident.
The social media company says that it will learn from the outage so that it never happens again. "Every failure like this is an opportunity to learn and get better, and there’s plenty for us to learn from this one. After every issue, small and large, we do an extensive review process to understand how we can make our systems more resilient. That process is already underway."

Popular stories






Latest News





Things that are NOT allowed:
To help keep our community safe and free from spam, we apply temporary limits to newly created accounts: