There is a lot of news around the newly proposed Do-Not-Track bill in the U.S. Senate, but it seems as though most of the coverage doesn't give both sides of the argument. Media has been good about covering the reasoning behind the privacy advocates and the purpose of the bill, but most do not mention the potential effects that a bill like this could have on the Internet and the ecosystem it powers.
The Do-Not-Track Online Act of 2011 has been proposed by the Chairman of the Senate Committee on Commerce, Science and Transportation Jay Rockefeller (D-W. Va). The bill would create a service by which people to opt-out of being tracked online, and give the FTC power to pursue companies that violate these rules. It can be likened to the Do Not Call list which prevents telemarketers from calling someone on the list; because, similarly the Do-Not-Track bill would allow people to opt-out of all tracking without having to opt-out of each tracking service.
Proponents of the bill and privacy advocates argue that someone's personal data is just that: personal, and so people should be able to control how that data is used. For example, if someone checks-in at a location on Facebook, they should have the choice as to whether or not that information is sold to advertisers, or shared with other companies. Also, the bill would stop companies from buying information from a person's search or shopping history in order to target advertising to that person.
Recommended For You
In those terms, sure tracking seems creepy, and it seems like a given that people should have this right. The thing is: people not only already have this right, but they have the tools to make it happen. And, many people don't understand the full benefits of tracking and ramifications of too many people choosing a Do-Not-Track option without understanding the whole issue.
Added Value
Let's not forget that our "private data" has been used this way for a long time before the Internet existed. Any time you filled out a raffle in a store, your address would then be sold to companies which would send you flyers in the mail. The Internet just makes the process more efficient. Let's also not forget that all of the "free" services on the Internet and on our mobile devices are not really free, but are more often than not ad-supported, and those ads are much more valuable when targeted to users based on their location and interests.
Targeted advertising is much more effective and profitable for businesses and advertising companies. If a company knows that you like to buy their brand of socks, they'll pay a little extra to send an advertisement your way, and they'll pay a little more to send that ad around the time it is likely that the last pair of socks you bought might be wearing out. And, the value isn't just added for those selling the ad or recommendations, but for users too.
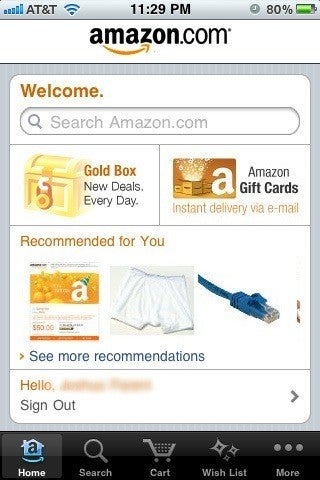
Think about it, what is the best thing about shopping on Amazon? The recommendations. Without tracking, Amazon wouldn't be able to learn your habits, and your preferences, and it wouldn't be able to recommend products based on the purchase habits of other customers. Those recommendations are a necessity online. We need to be able to draw on the wisdom of the crowd when shopping online, because we can't physically touch the product or try out the product. Not to mention, we may not know that there is something we should buy. We would lose that serendipity of finding a great new book simply because others who share our tastes liked that book.
The new trend of special deals wouldn't be possible without "personal data" either. Stores can't offer you coupons without getting your location, or knowing that you like a certain store or product.
Who are You?
Another trouble with this debate is that there is no demarcation between "personal data" and "personally identifiable data". While many companies may sell your location to a company to target an ad better, many times that company doesn't know who you are. The data doesn't know that Stephen Clarkson is in the area, it knows that there is someone with a mobile phone in this area, and maybe that person would like a cake from the shop around the corner. Or, the data knows that the person using your device likes to read stories about Seth MacFarlane, so a story about a new Family Guy DVD might be of interest, but there isn't necessarily a link to you personally.
There are companies that will put a name to that information, and there should be ways to stop that, but if companies were more clear about what information of yours is shared, people might not be so wary of sharing.
The Browser Push
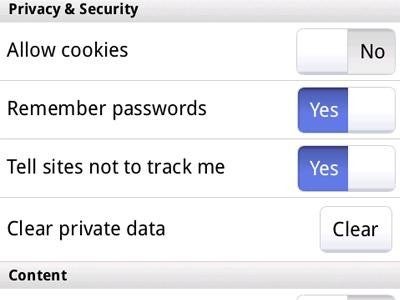
On a certain level, it seems like overkill to need a federal law for something like this, because the market has already pushed browser makers to add Do-Not-Track options, even atop those options that had already existed. For years, browsers have had the option to turn off cookies, which are most often used to track user behavior and history. More recently, browsers have been adding "private browsing" modes which not only don't allow cookies, but also do not keep any history of a user's activity.
Internet Explorer, Firefox and Chrome on desktops and Firefox for Android have all recently added Do-Not-Track options to their browsers already. Granted, the solutions are not yet comprehensive, and each have their flaws. As well, there is no standardized implementation of Do-Not-Track, but those kinds of things often get sorted out in time. In the mean time, we should be careful not to count "requiring work" by users as a flaw of any implementation.
Personal Responsibility
Requiring work on the part of the user is not a flaw, it is training. The world will not be going backwards; it will continue on forwards. Social is a trend that will continue on the Internet, so people have to be trained to control their own data. People have been trained to not fill out every flyer they get in the mail for "free products", and people have learned that maybe it isn't the best idea to tell a stranger where you live or what your name is. The same ideas need to be brought to the Internet.
People need to be educated about both the negative consequences as well as the benefits of sharing on the Internet, and people need to learn how to best navigate those choices. We need to teach people how to use their fancy new smartphones to turn off location tracking, and present both sides of the debate.
It is not all pure benefit for consumers, there are companies that are making quite a bit of money from this information. Google is probably the biggest example of that. Google's entire empire is built on the back of serving ads and making those ads more relevant and therefore more lucrative. But, we do need to keep in mind that while Google may be making big profits by using this information, that ad revenue has subsidized projects like Google Maps, Gmail, and even Android. So, any blanket reaction to the ills of online tracking will serve to not only punish those who would use your information maliciously, but those who use that information responsibly and at little risk to you. There need to be protections against abuse of tracking and personal information, but if those protections go too far, many of the benefits and "free" services that we've come to enjoy could start disappearing.
Get Visible as low as $20/mo for 1 year. Limited time offer with code: FRESHSTART
$20
/mo
$25
$5 off (20%)
Offer Ends 6.1.2026 at 11.59pm ET. New members get $5/mo off the $25/mg Visible plan, $35/mo Visible+ plan, or $45/mo Visible+ Pro plan for the first 12 months. Promo code FRESHSTART required at checkout.
Michael Heller is known for his clear and informative articles on mobile technology. He explores important topics such as the rollouts of 5G networks and the advancements in mobile payments, offering readers insights into the evolving tech landscape.
Recommended For You
COMMENTS (11)
COMMENTS (11)
All comments need to comply with our
Community Guidelines
PhoneArena Community Rules
A discussion is a place, where people can voice their opinion, no matter if it
is positive, neutral or negative. However, when posting, one must stay true to the topic, and not just share some
random thoughts, which are not directly related to the matter.
Things that are NOT allowed:
Off-topic talk - you must stick to the subject of discussion
Offensive, hate speech - if you want to say something, say it politely
Spam/Advertisements - these posts are deleted
Multiple accounts - one person can have only one account
Impersonations and offensive nicknames - these accounts get banned
To help keep our community safe and free from spam, we apply temporary limits to newly created accounts:
New accounts created within the last 24 hours may experience restrictions on how frequently they can
post or comment.
These limits are in place as a precaution and will automatically lift.
Moderation is done by humans. We try to be as objective as possible and moderate with zero bias. If you think a
post should be moderated - please, report it.
Have a question about the rules or why you have been moderated/limited/banned? Please,
contact us.















Things that are NOT allowed:
To help keep our community safe and free from spam, we apply temporary limits to newly created accounts: